



Data Warehouse
A central repository of information that can be analyzed to make informed decisions. Data flows into a data warehouse from transactional systems, relational databases, and other sources.
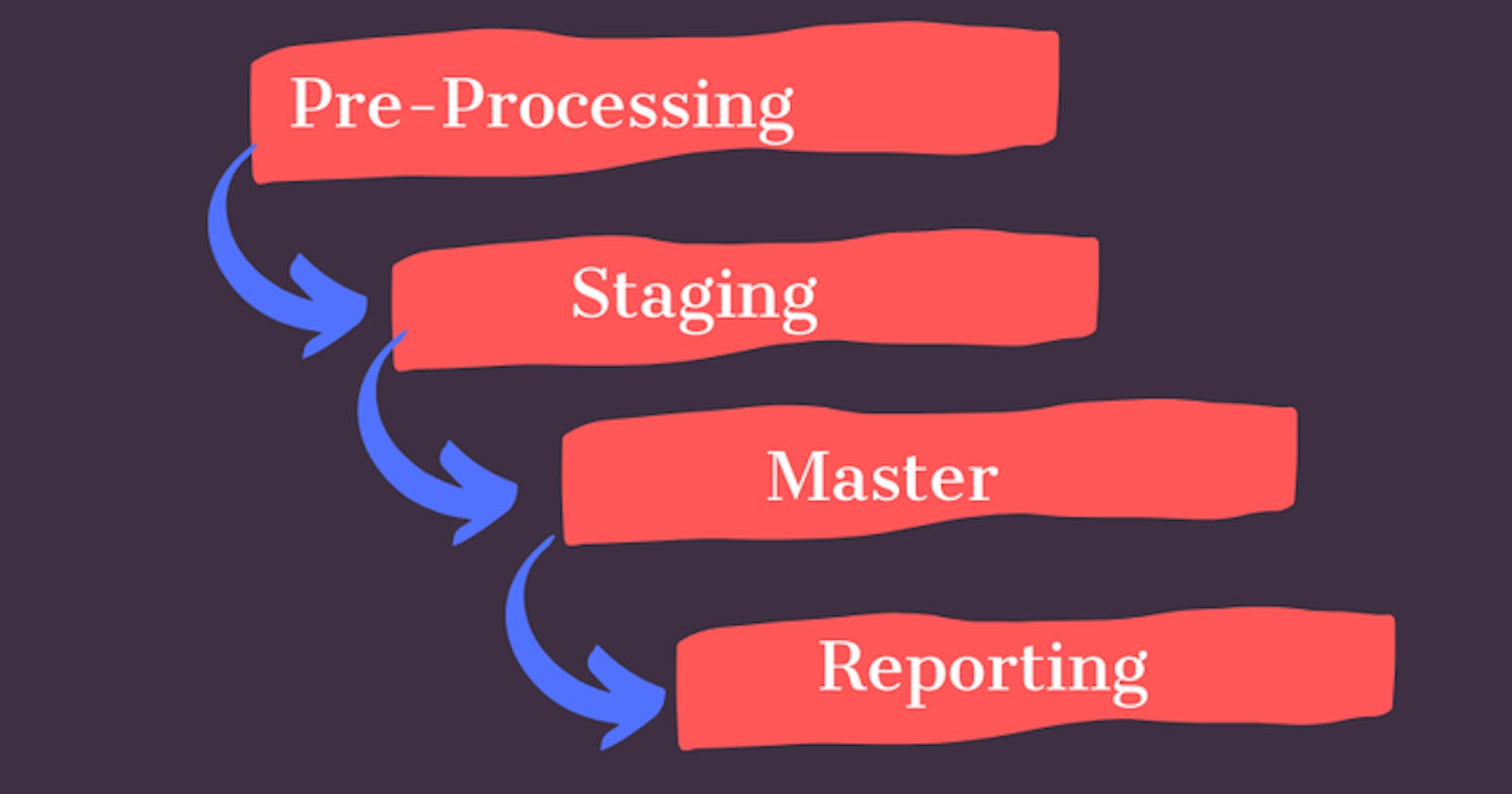
The core architecture boils down to some
Pre-Processing
After collecting data from various sources, consistency in the format is essential before loading into a data warehouse. In this step, our concern is with preparing data and validating data to maintain consistency in the format and we achieve it by using the following techniques.
Data Preparing
Dealing with missing values
- We can straight away delete the record containing the missing value but that can lead to bias and also reduce sample size.
- Another approach and mainly used is data imputation, we use column average, or can interpolate from nearby values, or can predict missing values. Some known techniques for data imputation are hot-deck imputation, mean substitution, and regression.
Dealing with outliers
- Outliers can be genuine or erroneous data points. To identify outliers the mainly used techniques are finding distance from mean or distance from the fitted line.
- For coping with outliers we can either drop, cap/floor, or set the data point to mean value.
Data Validation
- Certain field's value lies between a specific range, checking whether this criterion is matched or not.
- Check data type, some fields require specific kinds of data types like Boolean, Numeric, Date, or Timestamp. We have to validate it.
- Check for fields having compulsory constraints i.e specific columns shouldn't be having an empty value.
Staging
This is a holding area, where we put data after pre-processing (but not always) — and store it transiently until it’s processed further down the line. This is the last point where the data should be found in its raw form. (Amazon s3, Google Cloud Storage, etc are useful cloud products for staging area). It is recommended to have a staging area before loading data into the data warehouse. If storage is the concern we can archive the data after a reasonable duration.
Master
The master area is where the incoming data takes some real shape. The master schema should contain correctly modeled tables, that are appropriately named. Data Cleaning is mostly done here.
Data Cleaning
- Removing irrelevant data, remove data that doesn't fit the context of the problem or business KPIs.
- Remove duplicate values.
- Fix typos to have uniformity in data.
- Convert data types and check for any inconsistency in date format and timezone.
Reporting
Business analysts, data scientists, and decision-makers access the data through business intelligence (BI) tools, SQL clients, and other analytics applications. Businesses use reports, dashboards, and analytics tools to extract insights from their data, monitor business performance, and support decision making. These reports, dashboards, and analytics tools are powered by data warehouses. (To analyze data Amazon Redshift, Google BigQuery, etc are useful big data cloud products)
Key Point
Data Warehouse consists of highly curated data that serves as the central version of the truth, the data schema is designed prior to DW implementation (schema-on-write). DW is used for batch reporting, business intelligence, and data visualization by the business analysts.
Follow me on :