
Cloud Composer — GCE Persistent Disk Volume for KubernetesPodOperator

The Kubernetes executor was introduced in Apache Airflow 1.10.0. The Kubernetes executor creates a new pod for every task instance. Sometimes task requires to read configuration files or write output data to files.
This post explains how to add a GCE Persistent Disk to the GKE cluster using the ReadOnlyMany access mode. This mode allows multiple Pods on different nodes to mount the disk for reading. In case if we want to use the storage in ReadWriteMany mode, then something like NFS may be the ideal solution as GCE Persistent Disk doesn't provide such capability.
There are some restrictions when using a gcePersistentDisk:
the nodes on which Pods are running must be GCE VMs
those VMs need to be in the same GCE project and zone as the persistent disk
Let’s take a closer look at how we can configure it.
We need to start from creating a GCE persistent disk in the same region as cloud composer, attach it to a GCE VM.
Once the disk is attach to VM, we need to mount the disk. SSH into the VM and type the below command.
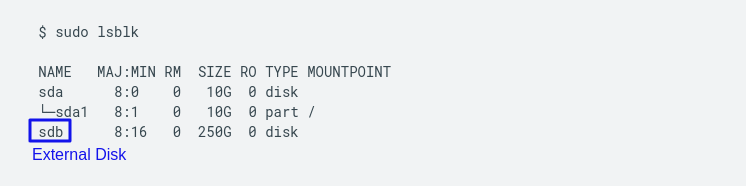
In this example, sdb is the device name for the new blank persistent disk.
- Format the disk
sudo mkfs.ext4 -m 0 -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/sdb
Replace sdb with the device name of the disk that you are formatting.
Create a directory that serves as the mount point for the new disk on the VM and give read and write permission on the disk.
sudo mkdir -p /mnt/disk # Creating mount directory
# mount the disk to the instance
sudo mount -o discard,defaults /dev/sdb /mnt/disk
# give read and write permission
sudo chmod a+w /mnt/disk
Now to populate this mount disk with data files, assuming data files are in local system, below command will upload data directory to the mount path.
# from host machine upload data directory to VM mount disk path:
gcloud compute scp --zone <zone> --recurse data <user>@<instance-name>:/mnt/disk
After the data files are prepopulated in gcs persistent disk, detach the disk from the VM.
We need to start defining our Persistent Volume Claim(PVC) and Persistent Volume (PV). To know more about PVC and PV, I have explained briefly about it in the below section.
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-volume
spec:
storageClassName: ""
capacity:
storage: 10G
accessModes:
- ReadOnlyMany
claimRef:
namespace: default
name: my-volume-claim
gcePersistentDisk:
pdName: my-persistent-disk
fsType: ext4
readOnly: true
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-volume-claim
spec:
storageClassName: ""
accessModes:
- ReadOnlyMany
resources:
requests:
storage: 10G
kubectl apply -f gce-persistent-volume.yml
And this is our scenario where we are asking for a PV that supports ReadOnlyMany mode in GCP. It creates for us a PersistentVolume which meets our requirements we listed in accessModes section but it also supports ReadWriteOnce mode.
PV that was automatically provisioned by GCP in forPVC supports two accessModes and so we have to specify explicitely in KubernetesPodOperator definition that we want to mount it in read-only mode, by default it is mounted in read-write mode.
from datetime import datetime
from airflow import models
from kubernetes.client import models as k8s
from airflow.providers.cncf.kubernetes.operators.kubernetes_pod import (
KubernetesPodOperator,
)
volume_mount = k8s.V1VolumeMount(
name="my-volume",
mount_path="/mnt/disk",
sub_path=None,
read_only=True,
)
volume = k8s.V1Volume(
name="my-volume",
persistent_volume_claim=k8s.V1PersistentVolumeClaimVolumeSource(
claim_name="my-volume-claim",
read_only=True # Pod Claims for volume in read-only access mode.
),
)
with models.DAG(
dag_id="my-dag",
schedule_interval=None,
start_date=datetime.datetime(2021, 7, 19),
) as dag:
kubernetes_min_pod = KubernetesPodOperator(
task_id="my_task",
name="my_pod_name",
cmds=[...],
startup_timeout_seconds=300,
arguments=[...],
env_vars={
"PATH_TO_DATA_DIR": "/mnt/disk/data", # ENV will be populated in the container.
},
namespace=...,
image=...,
volumes=[volume],
volume_mounts=[volume_mount],
)
Persistent Volume & Persistent Volume Claim
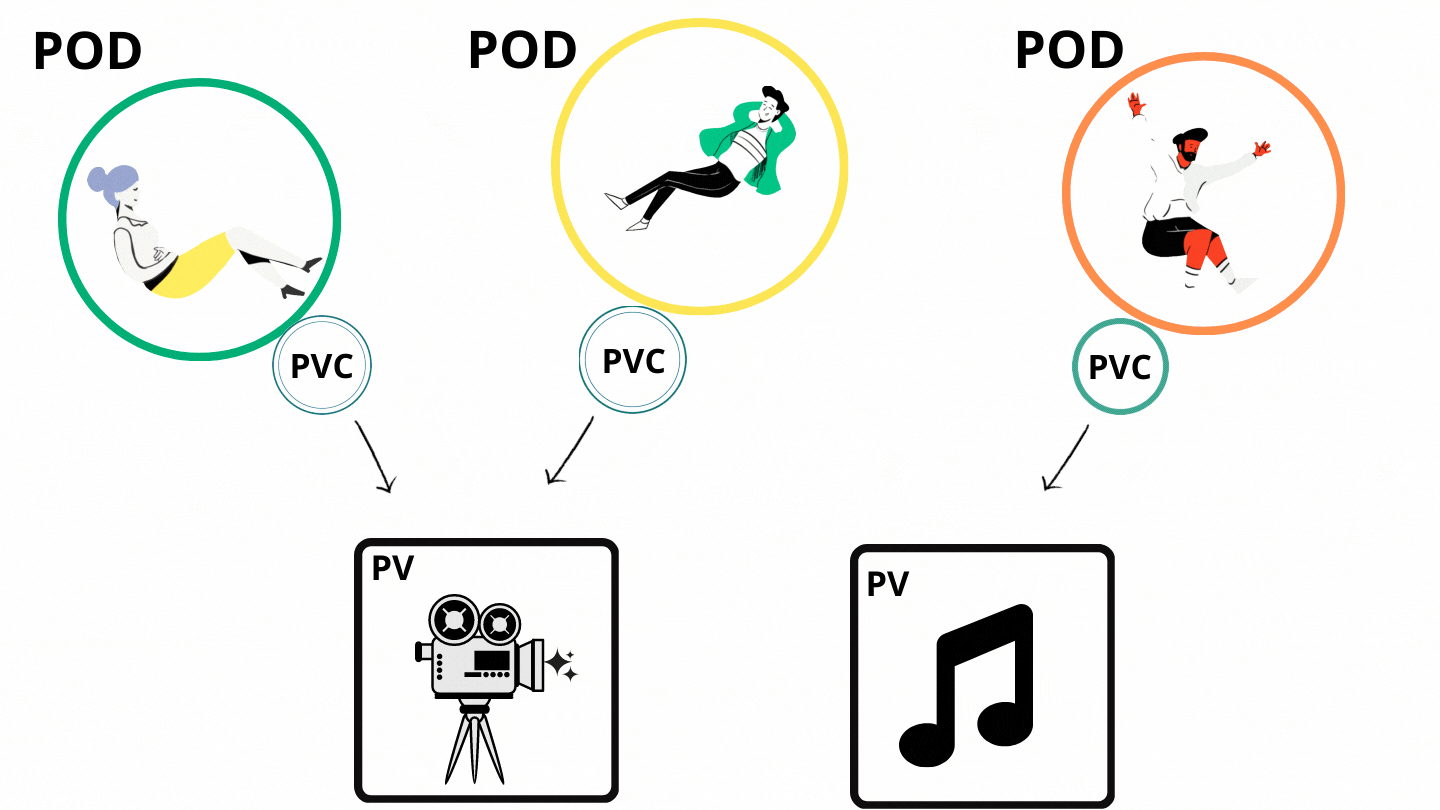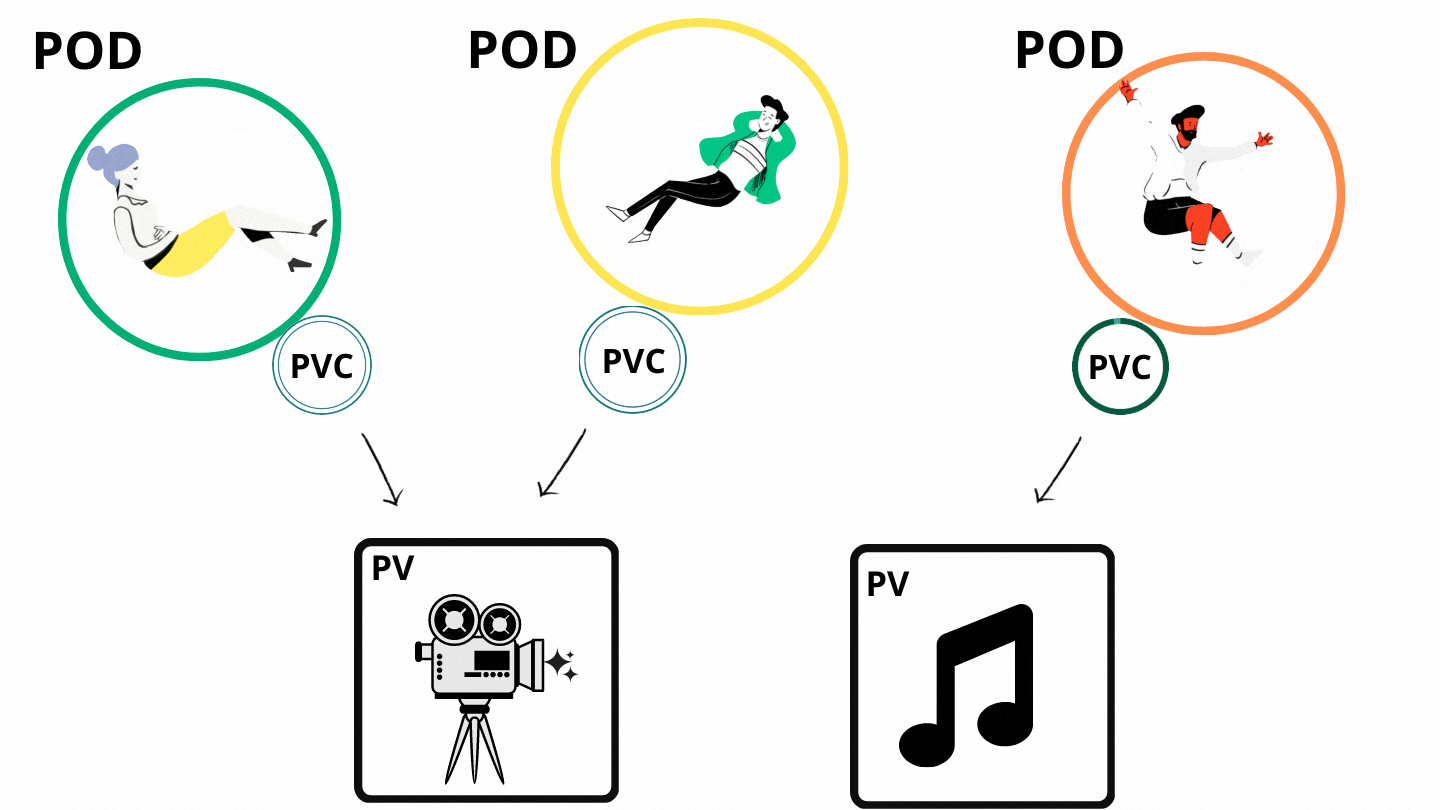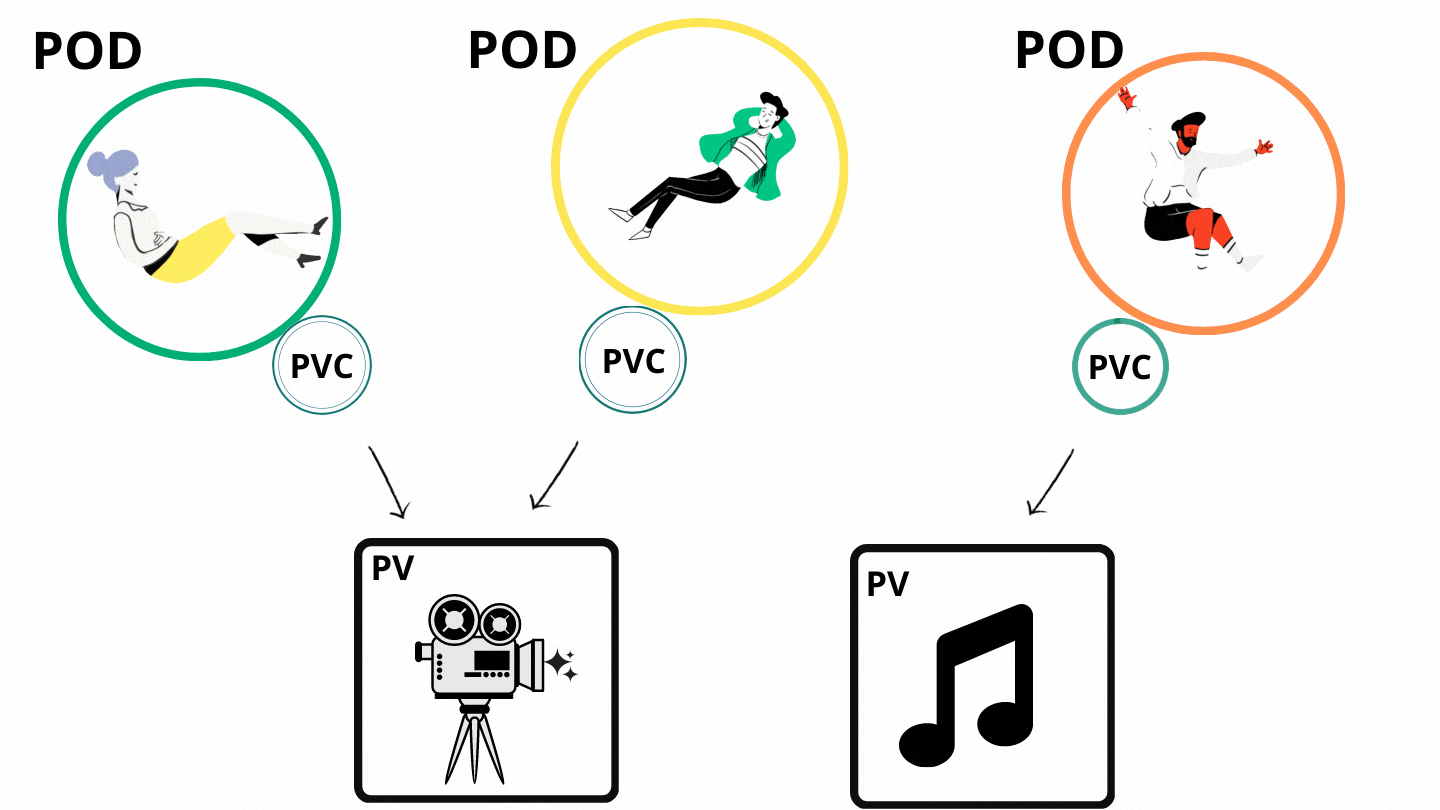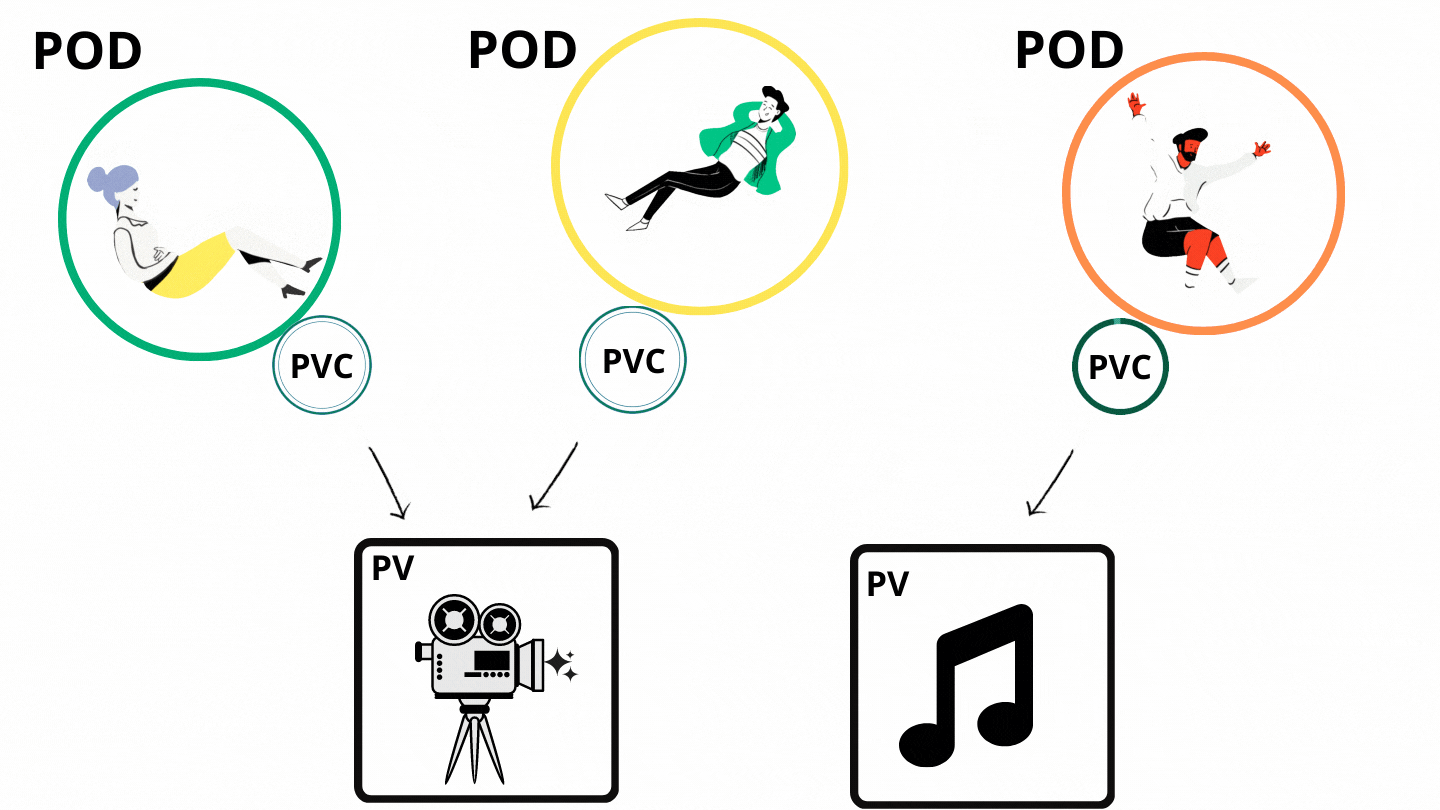
Persistent Volume, think of it as a cluster resource to store data or an abstract component which take the storage from the actual physical storage, like local hard drive, external NFS server, or a cloud storage. Kubernetes actually doesn’t care about storage so it gives us persistent volume component as an interface to the actual storage that a maintainer or adminstrator have to configured it and take care of . There are many types of persistent volumes that kubernetes supports. Persistent Volumes are not namespaced, that means they are accessible to the whole cluster.
Now, application that need to access the persistent volume has to claim the storage and kubernetes provide us with a component called Persistent Volume Claim. PVC claims a PV with certain storage size or capacity and some additional characteristic like access modes and whatever persistent volume matches this condition or satifies this claim will be used. Now, we have to use this claim in our Pod definition to access the PV. Pod request volume through the PV claim.
Basically it’s like saying:
“Hey, persistent claim! Give me a volume that supports ReadOnlyMany mode."
*Note: *Persistent Volume Claim must exists in the same namespace as the pod using the claim, whereas persistent volume are not namespaced and are accessible to the whole cluster.


