



In the previous post we understood what is a data warehouse and it's architecture. In this post, we are going to explore Data Lake.
Data Lake
If you think data mart as a store of bottled water - cleansed, packaged and structured for easy consumption - the data lake is a large body of water in a more natural state - James Dixon
A Data Lake is a central place where all company’s raw data flows, rapidly and provides a 360° view of the company’s data.
It is intended to be raw data - as close to the source as possible. It is still a good idea to capture the metadata and describe the data so that people can explore the lake and re-use what is available.
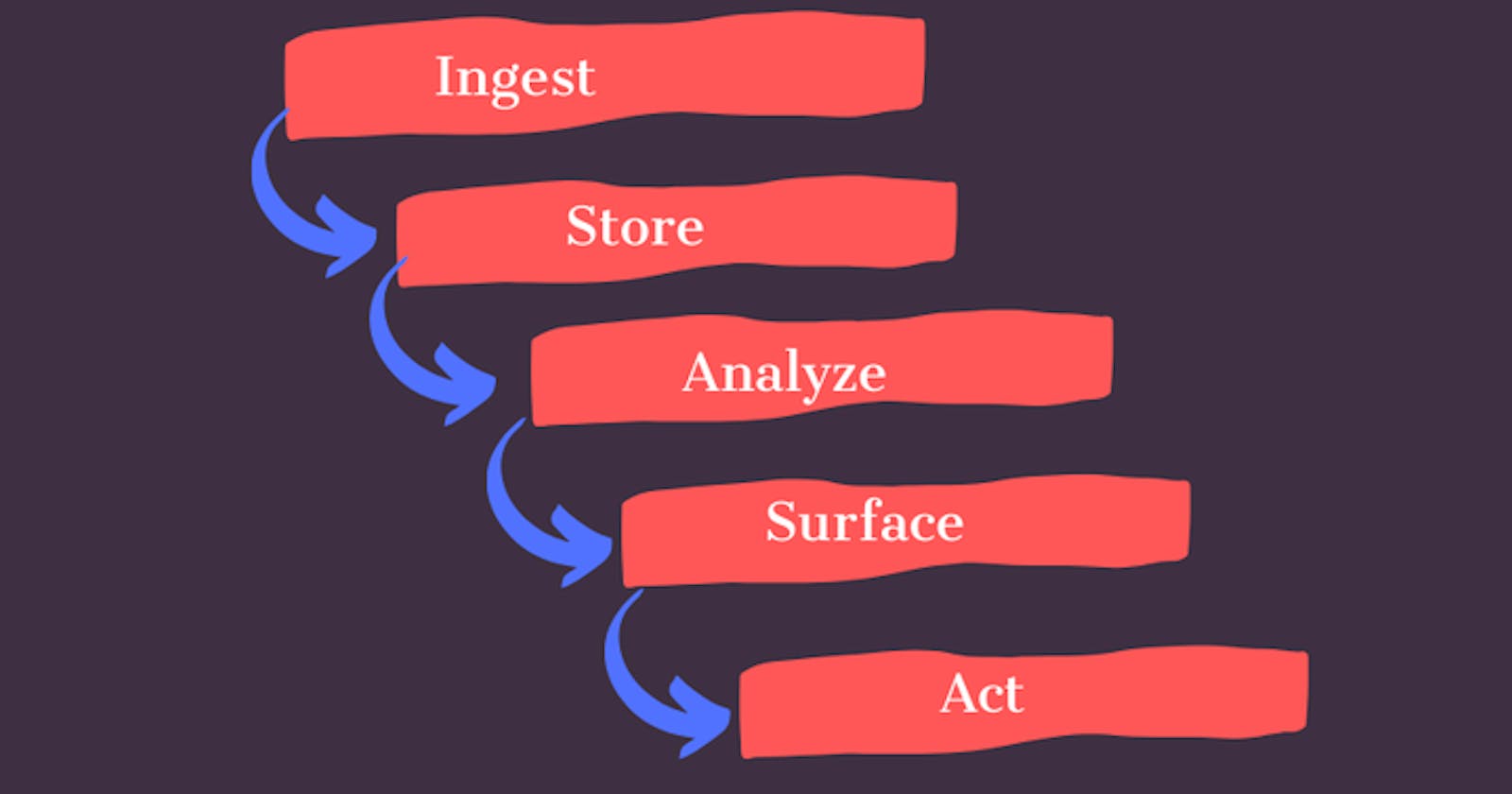
Data Lake comprises of these 5 major principles
Ingest
Ability to collect all data that businesses care about. Systems frequently ingest data through APIs and batch processing from various sources such as transactional systems, web scraping, relational databases, etc.
Store
Getting all data in one place and breaking down data silos. The storage should be scalable that supports storing structured, unstructured, and semistructured data.
Analyze
Matching correct data points and having correct systems and finding relations between all data gathered. Schema is written at the time of analysis (schema on read)
Surface
There needs to be a simple method to display all analysis. The data need to be understood here; the easier to see the result the easier to take actions.
Act
"Make Me More Money". A plan has to be put in place to take the results of data analysis and fit it into an operating business model.
The main challenge with a data lake architecture
Raw data is stored with no oversight of the contents. For a data lake to make data usable, it needs to have defined mechanisms to catalog, and secure data. Without these elements, data cannot be found, or trusted resulting in a “data swamp.”
For those who are thinking that how
Data Warehouseis different from a Data Lake, well to put it succinctly, proving the value of data is the role of Data Lake and In Data Warehouse one’s valuable data resides which they use for reporting purposes.
For data discovery and transformation of data stored in the data lake, we can set up an execution engine(Spark/Hadoop/Dremio) layer over the top of our data lake for a better understanding of data.
Follow me on